Word2Vec למתחילים 📒

רבים מכירים את ChatGPT ומשתמשים בו יום יום. הכלי הפך שם נרדף לטכנולוגיות בינה מלאכותית וזו ללא ספק מהפכה בדרך בה צורכים ויוצרים תוכן. שינוי התפיסה עורר בי עניין לתחום השפה. בפוסט זה נלמד את הבסיס בעולם עיבוד השפה הטבעית (NLP), על מודלי שפה בתחום ה-Word to Vector (בקיצור Word2Vec) ואיך בעזרתם נוכל לייצג משמעות סמנטית של מילים.
וקטורים #
מה הם? למה הם חשובים? וקטורים הינם אוסף מספרים שיחד המייצגים משמעות. וקטור מיוצג במרחב, ולכן בכל פעם שנוסיף מאפיין לוקטור, נוסיף גם מימד חדש. במקרה שלנו כל וקטור מייצג מילה, ולכן אם יש שני וקטורים קרובים נוכל להבין שמשמעות המילים קרובה. תהליך הטמעת מילים לוקטורים נקרא word embeddings.
כאנלוגיה ניקח את עולם המלוכה. אם ״נוציא״ את הגבריות ממלך ונוסיף לו נשיות, נוכל להסיק שנקבל מלכה. מה שעשינו בפועל זו פעולה מתמטית בין מילים. הפעולה המתמטית הביאה לתוצאה המתאימה ביותר שיכולנו לעלות על הדעת. בואו נצלול מעט ונראה איך זה עובד בפועל.
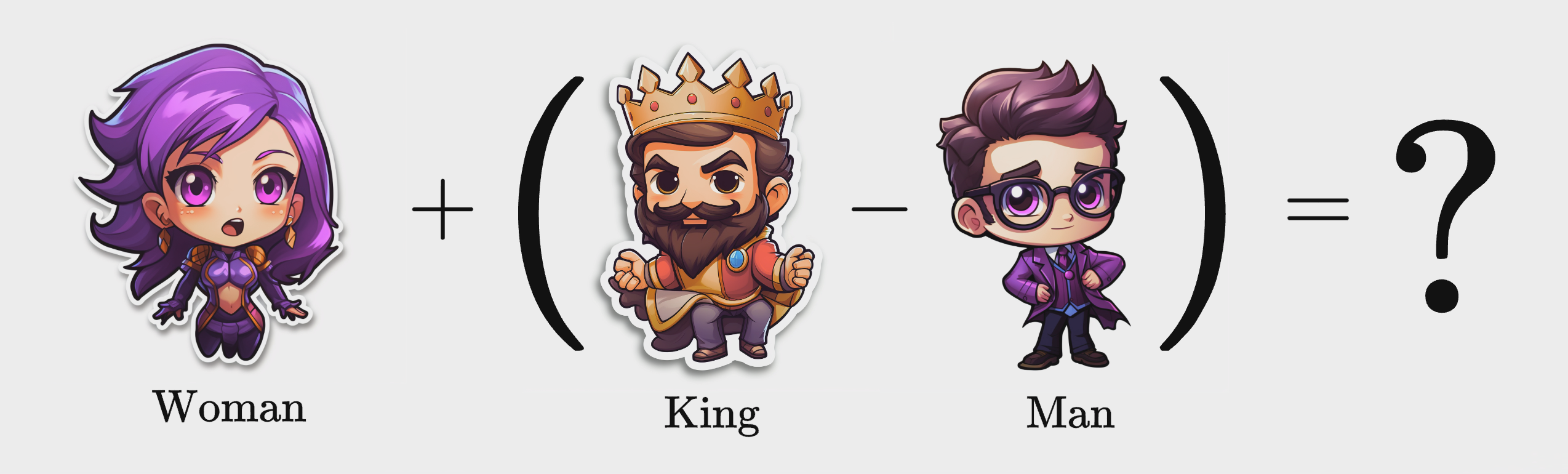
איך נראה וקטור? כיצד נוכל להשתמש בווקטורים? #
הצעד הראשון שאנחנו צריכים לעשות זה לבנות וקטורים המייצגים את המשמעות של כל מילה. במקרה שלנו, נרצה להבדיל בין מלך, מלכה, גבר ואישה ונבחר שלושה מאפיינים מרכזיים (Features Vectors): מלוכה, מגדר וכוח. מלך ומלכה נמצאים בממלכה, ולכן קיבלו 1.0 במאפיין המלוכה ובכוח. בנושא מגדר, גבר מקבל ערך מינוס-אחד ואשה פלוס אחד (מבלי לרמוז כמובן שגברים פחות טובים מנשים).
| Power | Gender | Royalty | Vectors |
|---|---|---|---|
| 1.0 | 1.0- | 1.0 | King |
| 0.5 | 1.0- | 0.0 | Man |
| 0.5 | 1.0 | 0.0 | Woman |
| 1.0 | 1.0 | 1.0 | Queen |
כל מאפיין של הוקטור מייצג מימד חדש, ובכך לכל אחד מארבעת הוקטורים שבנינו יש שלושה מימדים. דרך שילוב של שלושת המימדים, קיבלנו ייצוג של המשמעות של כל מילה ומילה.
הצעד השני הוא לחשב את התוצאה של הפעולה המתמטית, אותה נייצג עם שמות הווקטורים: ״King - Man + Woman״. ניקח את הוקטור המייצג את המילה ״King״, נחסיר את הוקטור של המילה “Man” ונוסיף את הוקטור של המילה ״Woman״. התוצאה תהיה וקטור חדש במרחב. נבחן איזו מילה הקרובה ביותר לוקטור התוצאה, ונראה שהמילה “Queen״ הקרובה ביותר. דרך דוגמא פשוטה זו נוכל להבין שהמודל למד קשרים בין מילים.
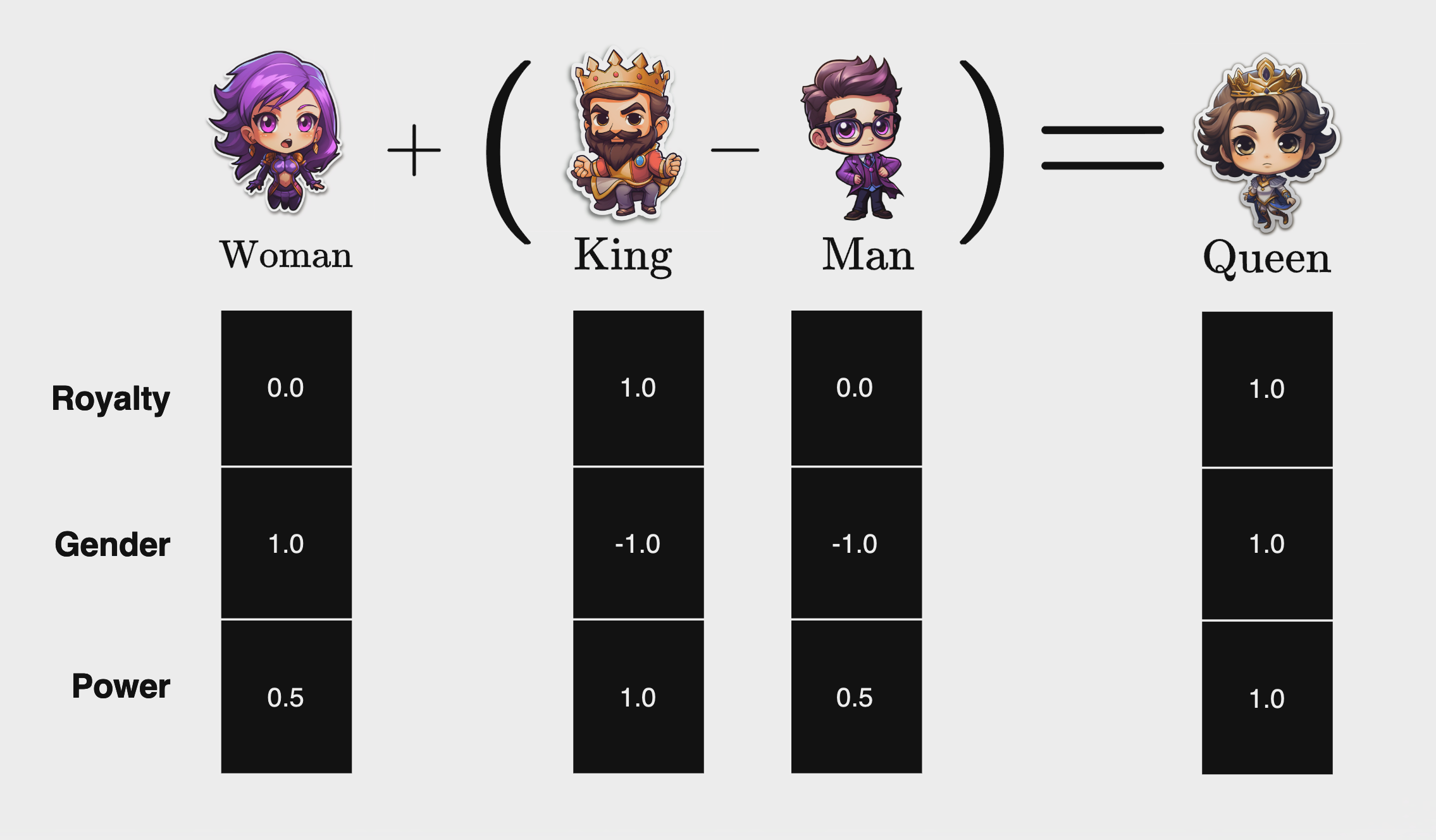
התוצאה שלנו מתאימה לייצוג הוקטור של המלכה בעולם ההיפותטי שיצרנו. שימו לב שדוגמא זו פשטנית; אם היינו צריכים לאפיין כל מילה ומילה בשפה, כמות המאפיינים יהיו אלפים, רמת הדיוק נמוכה והקושי יהיה רב. לכן, במודלי Word2Vec, ערכי ה-Features Vectors נקבעים בעזרת למידת מכונה כך שהוקטורים נפרשים על פני מרחב של מאות מימדים, וערכיהם לא ניתנים לפירוש על ידי בני אדם בצורה ישירה.
על מנת שלא נצטרך בצורה ידנית לעבור על כל מילה ומילה ולהחליט על ערכי ה-Features Vectors, ניעזר ברשת נוירונים שנאמן כך שעבור כל שתי מילים עוקבות, תחשב מה הסבירות שהמילה הבאה תהיה כל אחת מהמילים באוצר המילים שלנו. כתוצר לוואי של התהליך נקבל word embedding שכן עבור כל זוג מילים נקבל רשימה מתועדפת של ההסתברות לכך שמילה מסויימת היא העוקבת. מילים עם הסתברות גבוהה וקרובה הן ככל הנראה מילים עם משמעות קרובה במימדים מסויימים, גם אם לא משמעות זהה. מיד נצלול לדוגמא שתעזור להבין זאת טוב יותר.
הבעיה #
הבעיה שנרצה לפתור הוא השלמת מילה. במהלך האימון נשתמש בטקסטים רבים כחלק מה-dataset. לשם ההסבר כתבתי פסקה להדגמה:
ניקח משפט, לדוגמא עבור ההקשר (Context) ״ordered his ministers ____״ נמצא את המילה המתאימה ביותר, Target Word. מהניסיון שלנו אנחנו יודעים שהמילה intelligence לא מתאימה, גם לא the וגם לא time. יחד עם זאת, המילה Emperor כן מתאימה להקשר, וגם King. ובכך נוכל לשער שמשמעות שתי מילים אלו דומה.
Emperor ordered his ministers
אחרי שמצאנו בעיה שנרצה לפתור, נצטרך לבנות את ה-Dataset עליו נרצה לאמן את רשת הנוירונים בשיטת CBOW (קיצור של Continuous Bag of Words). ה-Dataset יורכב משני חלקים, Context ו-Target Word:
ordered, his -> King
gather, intelligence -> to
רשת נוירונים #
רקע #
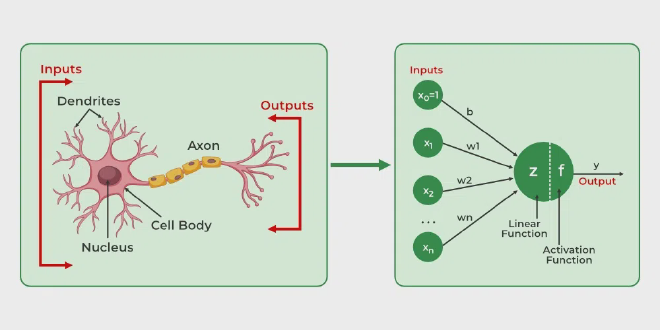
לפני שנתחיל לאמן רשת נוירונים על בסיס ה-Dataset שלנו, נלמד יחד רקע. נוירון (Neuron, לעיתים נקראים צומת Node) מהווה אבן הבניין הבסיסית ביותר של רשת נוירונים מלאכותית (Natural Network). מבנה הנוירון נלקח כהשראה מהמבנה הביולוגי של מוח האדם. בפועל, נוירון מקבל קלט, מבצע על בסיסו חישובים מתמטיים ומחזיר את התוצאה בתור פלט.
כאשר הרבה נוירונים מחוברים, נוצרת רשת נוירונים, אשר יכולה לקבל החלטות יותר מסובכות מנויורון בודד. מטרת הרשת היא להבין את הקשר בין הקלט לפלט. הרשת לומדת מדוגמאות מגוונות ומתאימה את עצמה, כך שתוכל לבצע חיזוי (Prediction) על פי מידע שלא ראתה.
נוירון #
מרכיבי הנוירון #
-
קלט (Input) - לכל נוירון מספר מוגדר של קלט. זהו שער הכניסה לנוירון, מעין צינור מקשר. הקלט יכול להיות גולמי חיצוני, ויכול להיות תוצאת חישוב של נוירון אחר ברשת.
-
משקלים (Weight) - לכל קלט יש משקל מתאים, שקובע את חשיבותו לקביעת התוצאה. בהתחלה, המשקלים מוגדרים בצורה רנדומלית, ובמהלך הלימוד ערכיהם מכוונים להגעה לחיזוי טוב יותר. אחרי תהליך האימון ערך המשקלים הופך קבוע.
-
הטיה (Bias) - פרמטר נוסף בנויורון המאפשר גמישות ותזוזה של הנוירון. ערך זה נוסף לסכום המשקלים.
תהליך חישוב #
- פונקציית סכימה (Linear Combiner) - עבור כל קלט הנוירון כופל את ערכו במשקלם התואם, וסוכם את תוצאת כפל כלל הקלטים (Weighted Sum). נוכל להבין, שאם המשקל קרוב לאפס השפעת הקלט המשויך לו תהיה מועטה על הסכום המצטבר, ובהתאם, להפך.
- הוספת הטיה (Added Bais) - אחרי שסכמנו את תוצאות הכפל, נוסיף הטיה לפונקציה. ההטיה מאפשרת לנו להתאים את פלט הנוירון באופן לא תלוי בערכי הקלטים.
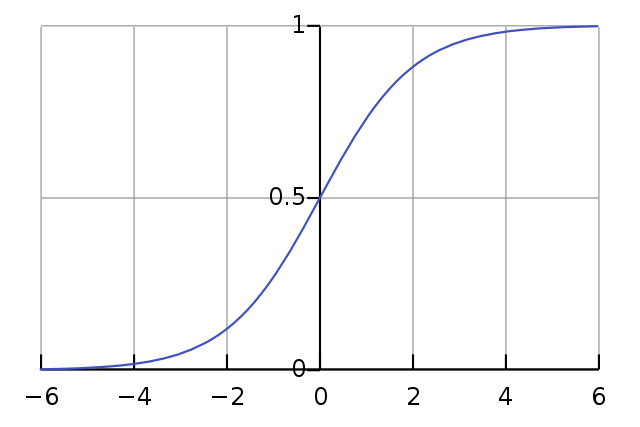
- פונקציית הפעלה (Activation Function) - נוסיף לסכום הכפל את ההטיה נקבל ערך אותו נכניס לפונקצית הפעלה. מטרת הפונקציה היא לחשב קשר לא-ליניארי בין קלט הנוירון לפלט. קיימים סוגים שונים של פונקציות הפעלה, ונתמקד במוכרת, Sigmoid function. פונקציה זו משנה את סכום הקלטים לטווח בין 0 ל-1.
אם נסכם, כל ניורון מקבל אוסף קלטים, מכפיל אותם במשקלים שנקבעו בזמן האימון, מוסיף הטיה ומכניס את התוצאה בפונקציית הפעלה. את התוצאה הוא מעביר לנוירון הבא או כפלט למשתמש.

רשת נוירונים #
מרכיבי רשת נוירונים #
רשת נוירונים מורכבת מאוסף נוירונים, ומורכבת ממספר שכבות (Layers), כאשר בכל שכבה יש מספר מוגדר של נוירונים. בפועל, הרשת מבצעת פעולות מתמטיקאיות פשוטות למדי, והחוכמה המרכזית היא המשקלים והמבנה של הרשת.
- שכבת קלט (Input Layer) - המידע שנרצה לעבד דרך רשת הנוירונים ייכנס. היא מקבלת raw input, ולאחר מכן מעבירה אותו לשכבות הבאות. מספר הנוירונים בשכבה מתכתבים עם כמות ה-Features ב-Dataset.
- שכבות נסתרות (Hidden Layers) - על בסיס הקלט, השכבות הנסתרות מבצעות חישובים. כל נוירון בשכבות הללו תורם לתשובה הסופית של הרשת. יכולים להיות איזו כמות שנרצה של שכבות נסתרות, ובכל אחת נוכל להגדיר כמה נוריונים יהיו.
- שכבת פלט (Output Layer) - על בסיס הקלט והעיבוד של הרשת, שכבה זו מחזירה את הפלט של החישובים. מספר הנוירונים בשכבה זו מתכתבים עם כמות האפשרויות לפלט.
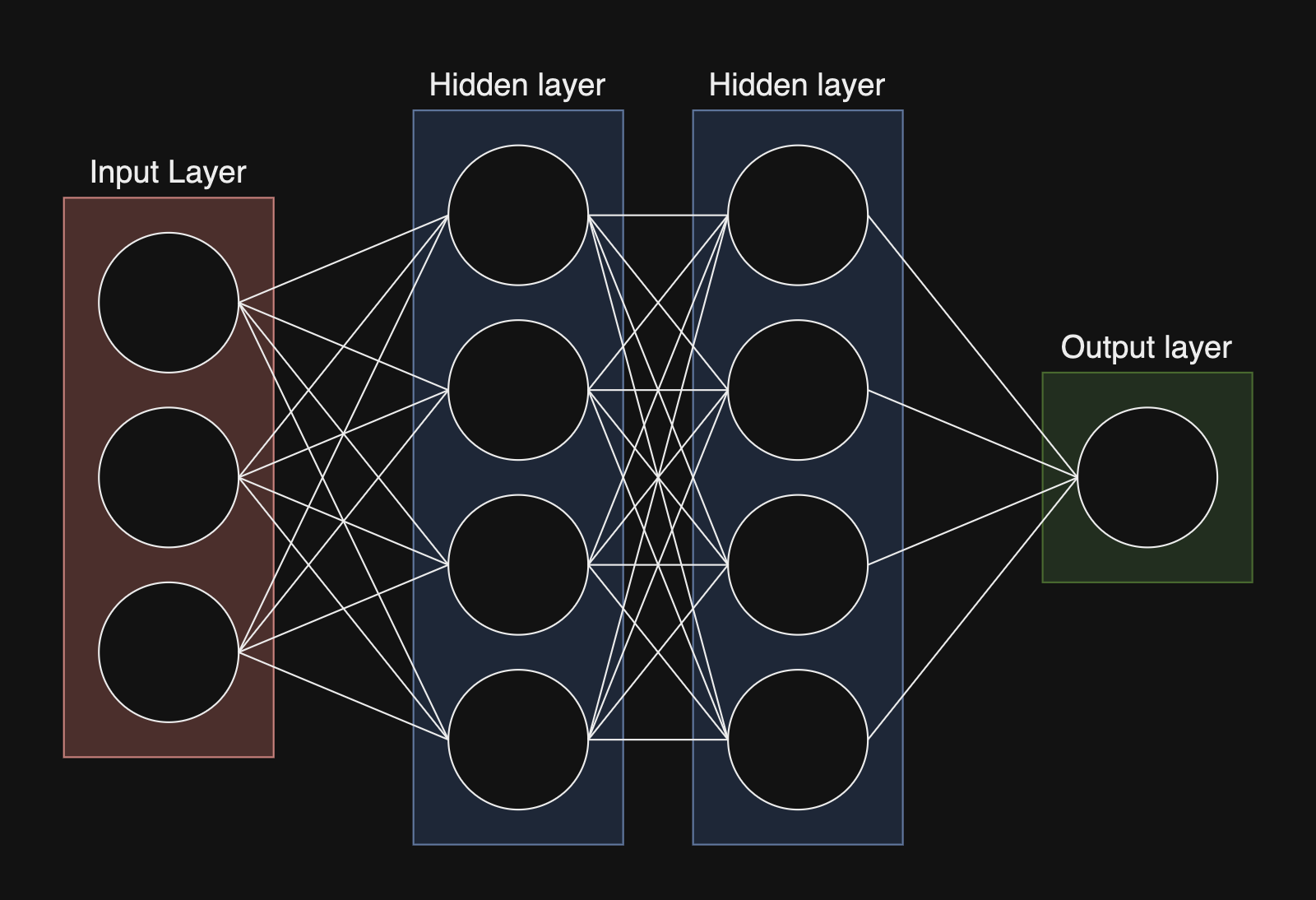
פעולות #
בכל רשת נוירונים קיים סדר פעולות באמצעותן משקלי הרשת מותאים ל-Dataset:
- Forward pass - רשת הנויורונים מקבלת קלט, מעבדת אותו על פי המשקלים של הנוירונים המכילים אותה, ומחזירה פלט. הפלט הוא בעצם התחזית (prediction) של רשת הנוירונים.
- Loss Function - טווח הטעות, הפרש בין התחזית לערך הנכון.
- Backward pass - לעיתים נקרא גם Backpropagation. בהינתן טווח הטעות, אלגוריתם זה מחשב את השפעת כל נוירון (משקלים והטיות). מדובר על תחום מתמטי רחב, תוכלו להעמיק במאמר הזה, Chain Rule of Calculus של אתר Machine Learning Mastery.
- Update parameters - אחרי שחישבנו חוזר לאחור (מפלט לקלט) נעדכו במעט את ערכי המשקלים, כך שטווח הטעות יקטן ככול הניתן (שיפוע הטעות). מדובר על נושאים לא מצומצמים, וגם על נושא זה לא ארחב במאמר זה.
למי שרוצה להעמיק, אני ממליץ על הספר Neural Networks from Scratch in Python מאת Harrison Kinsley (שמנהל את ערוץ היוטיוב הפופולרי sentdex) ו-Daniel Kukieła.
מימוש #
נניח כי אוצר המילים ב-Dataset הוא 5,000 מילים. נרצה לבנות אוסף וקטורים, המייצגים את כל מילה ומילה בטקסט. נגדיר וקטור עם 5000 תאים, תא לכל מילה באוצר המילים. כאשר נרצה לבנות ייצוג וקטורי עבור מילה מסויימת, ערך התא התואם לאותה המילה יהיה 1, ושאר התאים יהיו 0. אותו הוקטור נקרא Embedding vector.
לדוגמא, המילה ordered והמילה his:
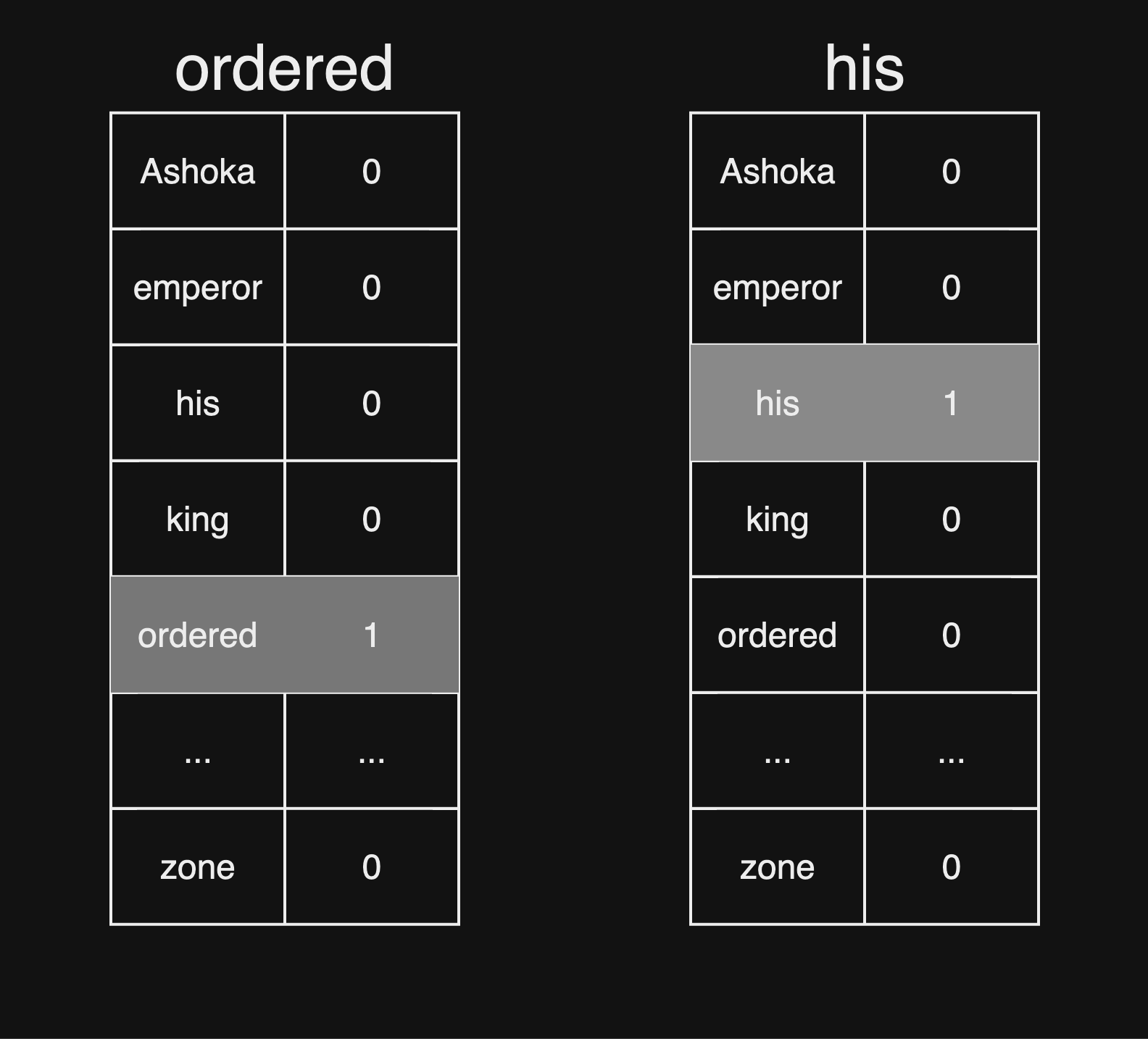
אחרי שיצרנו לכל מילה באוצר המילים וקטור נוכל לגשת לאימון המודל. לדוגמא ניקח את הוקטורים המייצגים את המילה ordered ואת המילה his. דרך ה-input layer, ערכי הוקטורים יכנסו לרשת הנוירונים, כאשר לכל קלט יש משקל ייעודי. הערכים יעברו דרך הנוירונים והשכבות השונות, ונקבל פלט בגודל זהה לוקטור המייצג מילה, במקרה שלנו 5000. התא עם הערך הגבוהה ביותר יהיה התחזית של רשת הנוירונים. בעזרת Loss Function נשווה בין התחזית לבין ה- Target Word, נבצע וויסותים למשקלים ולהטיות הנוירונים (Backpropagation) ונחזור על כך מספר פעמים.
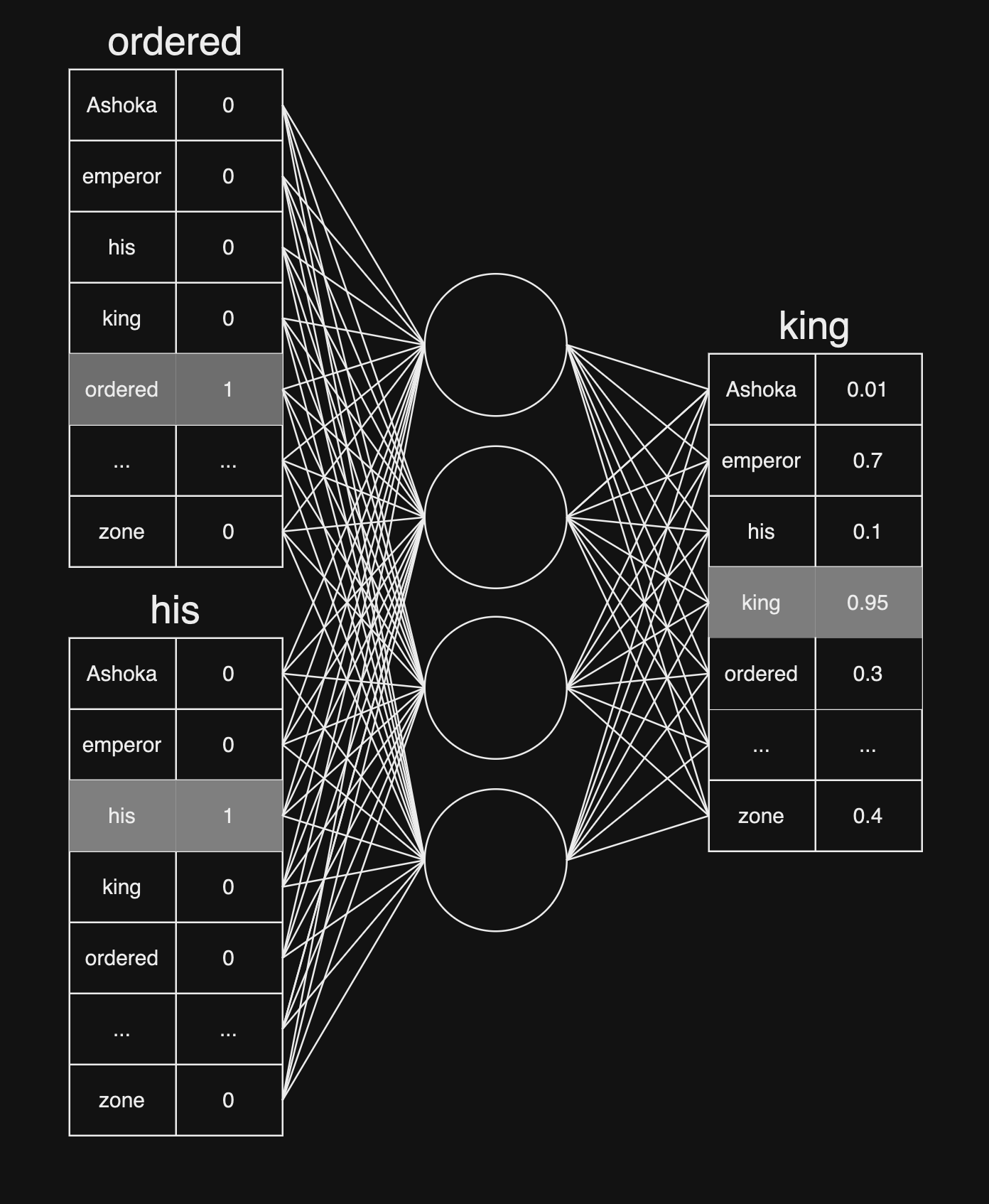
מה מתקיים במצב כאשר יש לנו מילים עם משמעות דומה? לדוגמא, לצירוף המילים ״ordered, his״ נוכל לשייך את המילה ״king״, אבל גם את המילה ״emperor״. בפועל, כאשר נכניס למודל את צירוף המודל ״ordered, his״, המשקלים לשכבת הפלט יהיו קרובים מאוד בין ״king״ ו-״emperor״:
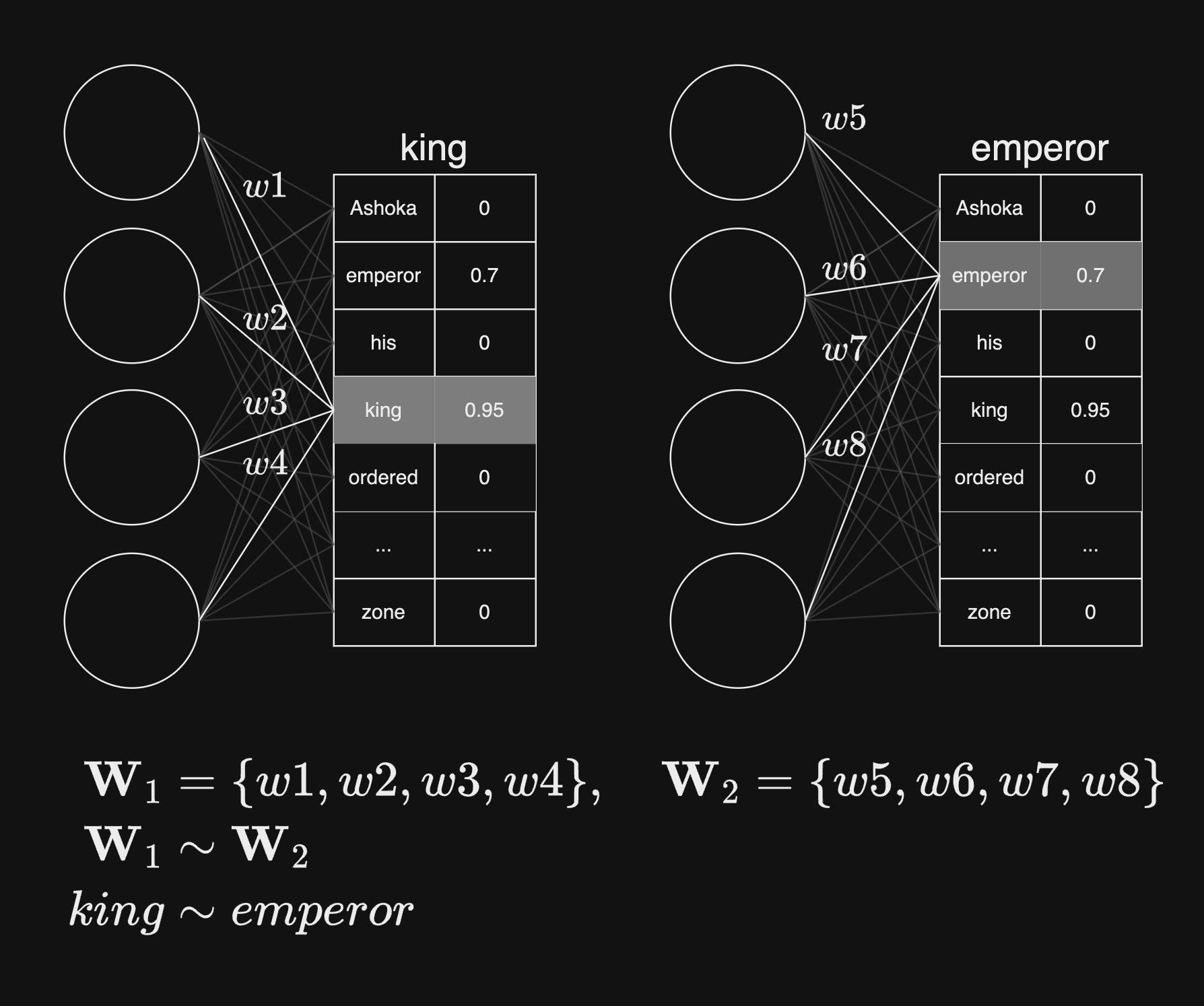
Python #
צעד ראשון - ייבוא ספריות #
לפני שנוכל להתחיל לייצר את המודל Word2Vec שלנו, נצטרך קודם לייבא את הספריות בהן נעשה שימוש.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import gensim
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
import nltk
from nltk.corpus import stopwords
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
צעד שני - Dataset #
השלב הבא הוא לייבא את ה-Dataset שלנו. חברת Amazon שחררה לפני כמספר שנים היסטוריית ההמלצות על מוצרים, תוכלו לבחור מפה את ה-Dataset שמעניין אתכם. אני בחרתי את meta_Electronics, המכיל 178 מיליון רשומות ושוקל 660MB.
df = pd.read_json("reviews_Cell_Phones_and_Accessories_5.json", lines=True)
df.shape
(194439, 9)
df.head()
| summary | overall | reviewText | helpful | reviewerName |
|---|---|---|---|---|
| Looks Good | 4 | They look good and stick good! I just don’t li… | [0, 0] | christina |
| Really great product. | 5 | These stickers work like the review says they … | [0, 0] | emily l. |
| LOVE LOVE LOVE | 5 | These are awesome and make my phone look so st… | [0, 0] | Erica |
| Cute! | 4 | Item arrived in great time and was in perfect … | [4, 4] | JM |
| leopard home button sticker for iphone 4s | 5 | awesome! stays on, and looks great. can be use… | [2, 3] | patrice m rogoza |
כפי שאתם יכולים לראות, ה-Dataset שלנו מכיל 9 עמודות וכ-200 אלף רשומות. בכל רשומה, יש לנו נתונים מזהים על נותן חוות הדעת, טקסט חוות הדעת (reviewText) וציון חוות הדעת. אנחנו נרצה ליישם את בעיית השלמת המשפט בעזרת reviewText. התוצאה תהיה מודל Word2Vec.
df.loc[0, 'reviewText']
"They look good and stick good! I just don't like the rounded shape because I was always bumping it and Siri kept popping up and it was irritating. I just won't buy a product like this again"
צעד שלישי - Preprocessing #
ספריית Gensim הינה Open Source, ומיועדת לבעיות Unsupervised בעולם עיבוד השפה. שמה הוא קיצור של Generate Similar, מתוך כך כבר נוכל להבין לייעודה- חילוץ הבנה מתוך הקשר בעזרת טקסטים. בשלב הבא נשתמש בה על מנת לבצע Preprocessing על כל חוות הדעת.
עבור כל רשומה, פונקציית gensim.utils.simple_preprocess מבצעת שלושה פעולות: מפרידה כל מילה ומילה לתא נפרד, מעדכנת את התאים כך שיהיו lower case, ומוחקת מילים קצרות מדי (2 אותיות) או ארוכות מדי (מעל 15 אותיות). אנחנו יכולים לשנות את ההגדרות שלה, אבל החלטתי להישאר עם ברירות המחדל.
review_text = df['reviewText'].apply(simple_preprocess)
review_text[0]
['good',
'just',
'don',
'like',
'the',
'rounded',
'shape',
'because',
'was',
'always',
'bumping',
'it',
'and',
'siri',
'kept',
'popping',
'up',
'and',
'it',
'was',
'irritating',
'just',
'won',
'buy',
'product',
'like',
'this',
'again']
אז עכשיו יש לנו Series שכל רשומה בו מכילה חוות דעת של לקוח. כל חוות דעת מפוצלת גם היא על פי מילה ל-Series. אתם יכולים לראות משהו מוזר? יש לנו לא מעט Stopwords. הן לא רלוונטיות למודל שלנו, הרי אנחנו רוצים להבין הקשרים בין מילים. התרומה של Stopwords יותר למבנה ולתחבר, מאשר להקשר המילים.
השתמשנו בספריית NLTK בעזרתה קיבלנו רשימה של Stopwords בשפת האנגלית.
# Download the set of stop words the first time
nltk.download('stopwords')
# Load the stop words
stop_words = list(stopwords.words('english'))
stop_words[:10]
[nltk_data] Downloading package stopwords to
[nltk_data] /home/ofir.linux/nltk_data...
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
אחרי שקיבלנו רשימה של Stopwords, נמחק מה-Dataset שלנו Stopwords. איך? נעבור על כל שורה ב-review_text, נשמור Series שמכיל רק את המילים שלא נמצאות ב-stop_words.
filtered_sentences = review_text.apply(lambda sentence: [word for word in sentence if word not in stop_words])
filtered_sentences[0]
['look',
'good',
'stick',
'good',
'like',
'rounded',
'shape',
'always',
'bumping',
'siri',
'kept',
'popping',
'irritating',
'buy',
'product',
'like']
צעד רביעי - יצירת מודל Gensim #
עכשיו, אחרי שיש לנו Dataset בסיסי עם כמות רשומות מספקות, נגדיר מודל Gensim.
פונקציית models.Word2Vec מקבלת 3 משתנים:
window- גודל חלון ההקשר, כמות המילים שנכניס למודל לפני ואחרי ה-Target Word. לדוגמא, במשפט the cat sat on the mat. המילה עליה אנחנו מתמקדים היא ״on״ והחלון שווה ל-2, אז ההקשר שיוכנס למודל יהיה [“cat”, “sat”, “the”, “mat”].min_count- רף שמגביל את כמות ההופעות המינימלית של מילים ב-Dataset. מילים עם שנמצאות פחות פעמים מהרף לא ייקחו בחשבון.workers- מספר ה-threads שיהיו בשימוש בזמן אימון המודל. המודל מאומן על ה-CPU המקומי של המחשב.
בנוסף, נוכל להגדיר epochs. עם זאת החלטתי להישאר עם ברירת המחדל של חמישה סבבים על ה-Dataset.
model = Word2Vec(
window=10,
min_count=2,
workers=4,
)
אחרי שהגדרנו מודל, נצטרך להגדיר את אוצר המילים שבו. ספריית Gensim צריכה לדעת אותן מראש להקצאת מקום אחסון טרם אימון המודל. פונקציית build_vocab מקבלת שני משתנים:
filtered_sentences- ה-dataset שלנו עליו נאמן את המודל, אחרי שעשינו Preprocessing בסיסי.progress_per- הצגת סטטוס התקדמות בעיבוד.
model.build_vocab(filtered_sentences, progress_per=1000)
צמד האותיות ״wv״ משמעותן Word Vectors: המילה עצמה, והייצוג הוקטורי שלה במרחב.
model.wv.index_to_key[:10]
['phone',
'case',
'one',
'like',
'great',
'use',
'screen',
'good',
'battery',
'would']
צעד חמישי - Training #
הגענו לשלב האהוב עלי, אימון המודל. נשתמש בפונקצייה model.train על מנת להתחיל את אימון המודל. נחקור את הפרמטרים שהפונקציה מקבלת:
review_text- ה-dataset שלנו עליו נאמן את המודל.total_examples- מספר המשפטים ב-review_text. נקבל אותם בעזרתmodel.corpus_count.epochs- מספר הפעמים שהמודל יחזור עלreview_textכחלק מהאימון, בעזרתmodel.epochs.
model.train(
review_text,
total_examples=model.corpus_count,
epochs=model.epochs
)
(39455685, 83868975)
יש! אימון המודל עבר בהצלחה. רגע, מה זה אומר ״(39455685, 83868975)״? התא הראשון מייצג את סך המילים שהמודל עיבד במהלך האימון, שהם 39,455,685. התא השני מייצג את כמות המילים אם לא היינו מגבילים את המודל (total_examples) שהם 83,868,975.
model.save("./word2vec-amazon-cell-accessories-reviews-short.model")
עכשיו שיש לנו מודל מאומן, נוכל לעשות מגוון פעולות איתו.
צעד שישי - Validation #
אחרי שאימנו את המודל, יש צעד מתבקש- לבדוק אותו! אני מצאתי לנכון לבדוק את המודל בעזרת שתי דרכים מרכזיות:
- חיפוש מילים קרובות למילה -
most_similar, מקבלת מילה ומציגה לנו רשימה ממויינת של המילים הקרובות למילה, עם רמת הקרבה הסמנטית מ-0 ל-1. - השוואה בין שתי מילים -
similarity, מקבלת שתי מילים, ומחזירה את רמת הקרבה הסמנטית מ-0 ל-1.
שמתי לב למשהו מעניין, המודל שלנו מזהה קרבה סמנטית בין מילים נרדפות, לדוגמא למילה “bad” המודל שיער בקרבה של 58% את המילים “ok” ו-״okay״. זה מסמן לנו שגודל ה-Dataset מצומצם, וכדאי להרחיב אותו. בלי קשר, הציונים יחסית נמוכים וזה גם מעיד על צורך להרחבה.
model.wv.most_similar("bad")
[('terrible', 0.7134353518486023),
('horrible', 0.6528913378715515),
('good', 0.6117088198661804),
('poor', 0.5842180252075195),
('ok', 0.5830951929092407),
('okay', 0.5794284343719482),
('sad', 0.5713397860527039),
('awful', 0.5661174058914185),
('guess', 0.5649060010910034),
('sucks', 0.5634702444076538)]
model.wv.similarity(w1="cheap", w2="inexpensive")
0.5494996
model.wv.similarity(w1="great", w2="good")
0.75265694
צעד שביעי - בחינת הוקטורים #
יש לנו מודל, ויש לנו אוצר מילים. שיחקנו קצת איתו וראינו הקשרים סמנטים בין מילים. בואו קצת נבין איך הוקטורים נראים, ולאחר מכן נעשה PCA.
איך נוכל לגשת לערך של הוקטור הראשון שלנו ב-Word Embedding? כמו שלמדנו מקודם, אובייקט המודל שלנו מכיל את הוקטורים - model.wv. דרך index_to_key נוכל לגשת למילה, ודרך vectors נוכל לגשת לוקטור המייצג שלה.
first_word = model.wv.index_to_key[0]
first_vector = model.wv.vectors[0]
print(f"The first word is: {first_word}")
print(f"The corresponding vector is: {first_vector}")
The first word is: phone
The corresponding vector is: [ 0.5008796 0.15167381 2.333319 0.10688468 -1.8840703 -1.6957991
0.05495637 0.05827418 0.2887405 -1.5429118 0.7645639 1.5215374
-1.0641086 -2.0851662 1.9897771 1.7530214 -1.4697678 1.203952
-0.5528912 0.86333096 0.34154853 0.40921074 1.8353231 -0.70408404
0.7073904 0.26164898 -0.49617675 -1.1880581 -1.7986948 -0.54001534
-1.6011297 -0.71133554 0.06995012 -0.771902 1.0777777 0.54750687
0.4895541 -0.19904068 -0.75305825 0.20286536 -0.12561971 0.6058311
-1.7315526 0.21385051 -0.29921278 2.2685251 0.23338611 1.1759087
-0.4928176 1.200081 0.16036424 1.461912 -0.27610686 0.78729796
-1.3324577 -2.002154 -1.886145 -1.2060144 0.09603836 0.441084
-0.84192204 1.3879699 -1.5583698 -2.1753058 1.8789396 1.8851941
2.532747 -3.5517168 4.300643 1.8870016 -0.13734312 -1.1338986
0.37865153 -3.2530427 0.2187101 0.08842526 -0.7187293 -1.6173351
-2.2799978 -2.930807 1.586075 1.0674981 0.0357586 -0.2196174
0.55386424 0.47894716 0.58673614 -1.2975037 -2.2414744 0.854725
0.24780588 -1.8748467 1.1259404 -0.6548109 0.7133601 -0.99056697
-2.082928 -1.9393501 -0.1883115 1.9074923 ]
בואו נעמיק קצת ונציג את הוקטור על גרף:
plt.figure(figsize=(12, 4))
plt.plot(first_vector)
plt.title(f"Vector for Word: '{first_word}'")
plt.xlabel('Dimension')
plt.ylabel('Value')
plt.show()
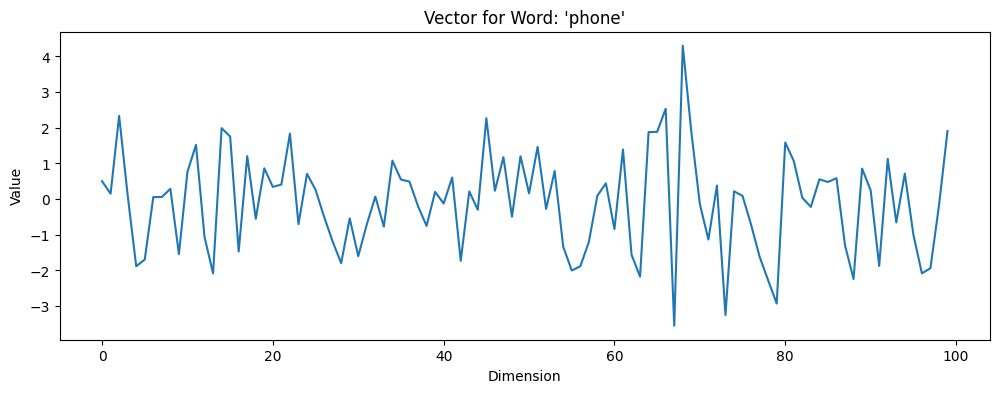
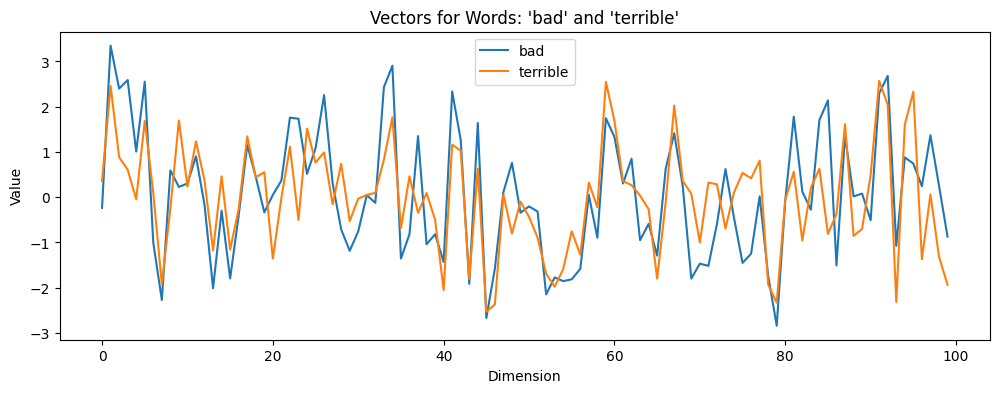
למרות שיש למודל שלנו 100 מימדים, איך בפועל הצלחנו לראות אותו? עבור כל מימד (שמייצג על ידי תא נפרד במערך first_vector), בדקנו מה הערך המתאים לו. לאחר מכן, יצרנו plot בסיסי. להעמקה נוספת, היה מעניין לראות וקטורים של מילים זהות ממקום, שנוכל לראות בצורה ויזואלית מדוע המודל החליט שהם קרובים.
bad_vector = model.wv['bad']
terrible_vector = model.wv['terrible']
plt.figure(figsize=(12, 4))
plt.plot(bad_vector, label="bad")
plt.plot(terrible_vector, label="terrible")
plt.title("Vectors for Words: 'bad' and 'terrible'")
plt.xlabel('Dimension')
plt.ylabel('Value')
plt.legend()
plt.show()
צעד שמיני - יצירת PCA והצגה גרפית #
PCA או בשמו המלא Principal Component Analysis, מפחית את כמות המימדים במקביל לשאיפה לשמירת רוב המידע. נשתמש ב-PCA על מנת לייצר וויזואליזציה של הקשרים בין מילים.
כמו שראינו מקודם, לכל וקטור במודל שלנו יש 100 מימדים. כל מימד מסמל משמעות מסויימת לכל מילה, שימוש במשפט והקשר בין מילים. PCA מאפשר להמיר את היחסים הללו לגרפים עם מימדים שאנחנו נוכל להבין.
common_words = model.wv.index_to_key[:250]
common_vectors = model.wv[common_words]
pca = PCA(n_components=2)
pca_result = pca.fit_transform(common_vectors)
pca_result[:10]
array([[ -2.8586824 , -2.0252922 ],
[-10.519664 , -0.06634452],
[ 0.4119802 , 2.6990404 ],
[ -3.819451 , -1.0890281 ],
[ -1.0121241 , 0.6645675 ],
[ 3.1565413 , -2.0301502 ],
[ -9.929559 , 1.2011172 ],
[ -2.5529263 , 0.71880364],
[ 10.047557 , -0.7733079 ],
[ -0.8474419 , 0.74553484]], dtype=float32)
pca_df = pd.DataFrame(pca_result, columns=['x_values', 'y_values'])
pca_df['word'] = common_words
pca_df.head()
| word | y_values | x_values | index |
|---|---|---|---|
| phone | -2.025292 | -2.858682 | 0 |
| case | -0.066345 | -10.519664 | 1 |
| one | 2.699040 | 0.411980 | 2 |
| like | -1.089028 | -3.819451 | 3 |
| great | 0.664567 | -1.012124 | 4 |
| … | … | … | … |
| drop | 0.963806 | -8.024269 | 245 |
| said | 4.825479 | -0.982296 | 246 |
| chargers | 0.804604 | 11.564008 | 247 |
| left | -3.246815 | 2.390023 | 248 |
| card | -1.351355 | -1.503416 | 249 |
לקוד שכתבנו יש 3 חלקים מרכזיים:
- וקטורי מילים - ניגש ל-250 מילים השכיחות במודל,
index_to_keyממויין מהמילה השכחיה ביותר ומטה. - יצירת PCA - השתמשנו בספריית sklearn. שמה המלא הוא scikit-learn. ספריה זו מהווה ארגז כלים ייעילים ופשוטים (תלוי עם מי מדברים) לניתוח נתונים ובניית מודלים.
בעזרתn_componentsהגדרנו את כמות המימדים שנרצה לקבל מ-PCA. לאחר מכן, קיבלנוpca_dfשמכיל את המילה, עם ייצוג בציר x וציר y. - ריכוז df - אחרי שיש לנו לכל וקטור את הערך ״המוקטן״ שלו בשני הצירים במערך
pca_result, נחבר יחד ל-df אחיד בשםpca_df.
בואו נראה איך pca_df נראה על גרף.
plt.figure(figsize=(12, 8))
plt.scatter(pca_df['x_values'], pca_df['y_values'])
for i, word in enumerate(pca_df['word']):
plt.annotate(word, (pca_df['x_values'].iloc[i], pca_df['y_values'].iloc[i]))
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title('Word2Vec Word Embeddings Visualized with PCA')
plt.show()
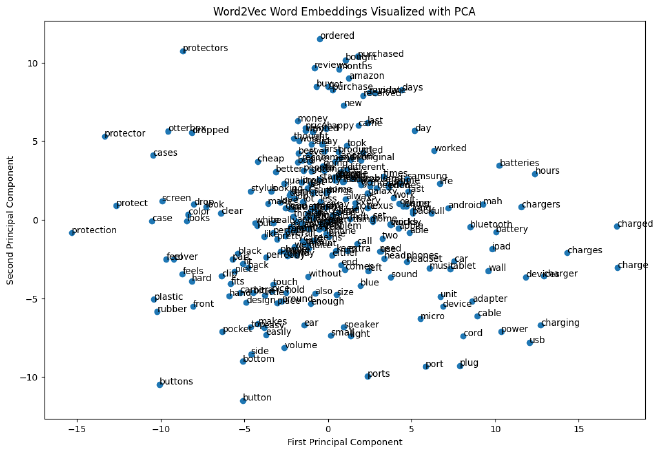
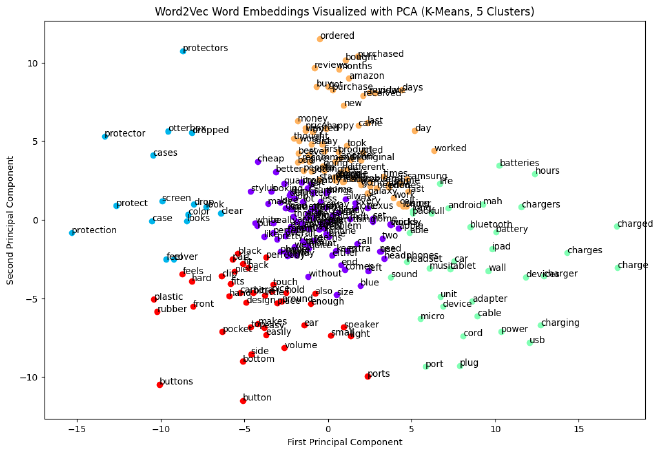
טוב אז יש לנו גרף שמראה את Word Embedding שעשינו. השלב המתבקש הבא הוא לייצר Clusters ממנו.
קודם כל, נצטרך לייצר את ה-clusters שלנו. רגע, מה זה אומר בכלל? Clusters בשימוש בבעיות Unsupervised כאשר רוצים לחלק את ה-Dataset ל-K חלקים (בקוד שלנו num_clusters), בתנאי שהם חופפים את אותו האזור בגרף.
# Number of clusters
num_clusters = 5
# Fit K-means
kmeans = KMeans(n_clusters=num_clusters, n_init=10)
pca_df['cluster'] = kmeans.fit_predict(pca_result)
יצרנו אובייקט kmeans עם 5 חלקים. לאחר מכן בעזרת פונקציית fit_predict חילקנו את המערך pca_result ל-5 חלקים.
השלב הבא, הוא להציג את ה-clusters היפים שעשינו בגרף. בגלל שלדעתי יותר יפה להציג כל cluster בצבע אחר, נגדיר מערך colors שיכיל צבעים שונים כמספר ה-clusters שלנו.
לאחר מכן, עבור כל cluster נגדיר scatter ב-figure משותף, ונוסיף תוויות עם ערך המילים.
מומלץ להקדיש מספר דקות להסתכל על המילים וה-clusters שיצאו לנו.
plt.figure(figsize=(12, 8))
colors = cm.rainbow(np.linspace(0, 1, num_clusters))
for cluster, color in zip(range(num_clusters), colors):
cluster_df = pca_df[pca_df['cluster'] == cluster]
plt.scatter(cluster_df['x_values'], cluster_df['y_values'], color=color)
for i, word in cluster_df['word'].items():
plt.annotate(word, (cluster_df['x_values'].loc[i], cluster_df['y_values'].loc[i]))
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.title(f'Word2Vec Word Embeddings Visualized with PCA (K-Means, {num_clusters} Clusters)')
plt.show()
מקווה שחידשתי לכם דבר אחד או יותר, נתראה במאמר הבא! 😀